はじめての統計学~データの種類について~
公開日
2022年1月26日
更新日
2026年7月26日

こんにちは。和からの数学講師の岡本です。前回に引き続き「はじめての統計学」というシリーズで今回はデータの種類についてまとめていきたいと思います。データはその種類によって扱い方や分析手法の難易度までかなり変わってきますので、実は非常に重要なポイントになります。なお前回の内容はこちらから!
この記事の主な内容
1.データの種類
データは大きく分けて2種類あります。前回扱った会社のデータを使って説明していきましょう。
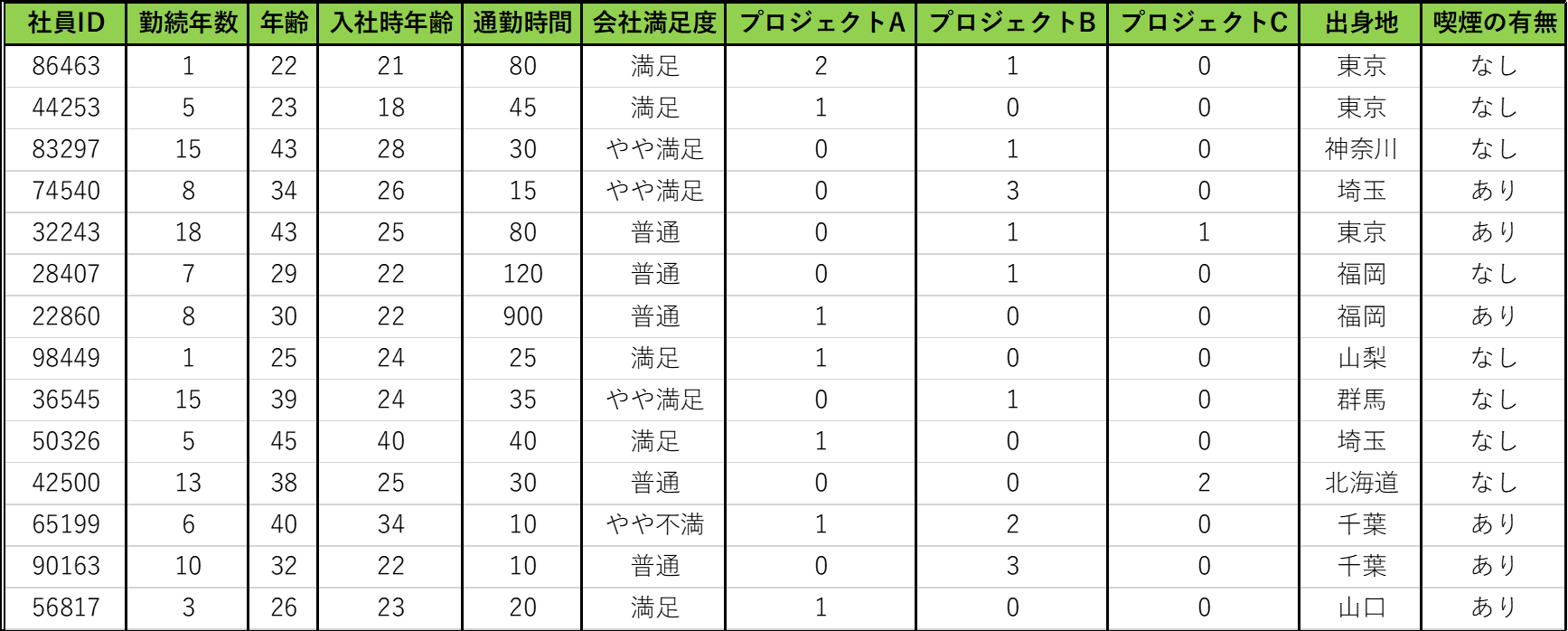
1つは数字タイプのもので、量的データ(quantitative data)といい、もう一つは文字タイプのもので質的データ(qualitative data)といいます。例えば勤続年数や年齢は量的データで、出身地や喫煙の有無は質的データになります。注意しておきたいのは社員IDです。これらは一見すると数字のデータに見えますが、足し算に意味を持ちません。例えば「平均ID番号」なんて聞いたことありませんよね。こうしたデータは単なるナンバリングであり、数字を使って区別するための名前にすぎません。したがって、普通は質的データとして扱うことが多いです。なお、質的としてコンピュータに認識してもらうため、アルファベットを混ぜたIDがよく使われます。
2.量的データ
年齢やプロジェクト数のように、とびとびの値であるようなものを離散型(discrete type)といい、体温や体重などのように、隙間なく連続的に値をとりうるものを連続型(continuous type)と呼びます。

また、量的データの中でも大きく2つの種類に分かれます。1つは間隔や差に意味がある間隔尺度(interval scale)で、もう1つはさらに数字の比を考えることもできる比率尺度(ratio scale)です。多くの量的データは比率尺度ですが、例えば体温や気温などの「温度」の変化は比率では表現しません。「昨日より気温は5%上がった」なんて聞かないですよね。これは、「0℃」という温度があり、他の温度と同等に扱えるからです。対して、例えば売上が「0」というのは、「無」という絶対的な意味を持ちます。これにより「0」を起点とし、比率を考えることができ、売上は比率尺度となります。
3.質的データ
質的データにも大きく2種類に分かれます。1つは、名前として区別するための名義尺度(nominal scale)、そしてもう1つは文字のデータではあるものの、「不満, やや不満, 普通, やや満足, 満足」という具合に順序が定まる順序尺度(ordinal scale)です。
社内データの例でいうと、出身地は名義尺度で、満足度は順序尺度になります。なお、社員IDに「入社順」の情報が入っている場合、順序尺度と捉えることができます。満足度のように順序尺度は数値に置き換えることができるのも大きな特徴です。
今回の満足度の場合、不満と満足という具合に、相反する方向の選択肢があります。この場合、「不満, やや不満, 普通, やや満足, 満足」を「-2, -1, 0, 1, 2」と置き換える方法が考えられます。その他にも、「佳作, 優秀賞, 最優秀賞」は例えば「1, 2, 3」と置き換えることもできます。
・量的データと質的データの例

最初にもお話したように、データの種類によってそのデータの可視化や分析手法は大きく変わってきます。そのため、データを見る際はまずそのデータが量的なのか質的なのかは意識して認識することにしましょう!
●和からのセミナー案内
集計やデータの活用に関するスキルは自然に身に付くものではありません。和からでは、社会人のためのデータ集計・利活用の講座をいくつか実施しております。興味のある方は是非一度無料講座へお越しください。
●参考文献
人文・社会科学の統計学 (基礎統計学) 東京大学教養学部統計学教室(編) 東京大学出版会
●和からのセミナー一覧はこちら
●お問い合わせフォームはこちら
<文/岡本健太郎>


新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →