テキストデータ分析のキホン-第1回:数字だけでは分からない“理由”を読み解く!テキストデータ分析の全体像【統計学をやさしく解説】
公開日
2026年1月30日
更新日
2026年5月6日

この記事の主な内容
この記事のポイント
・数字だけでは見えない「顧客や現場の理由」をテキストから読み解く
・テキストデータ分析の 4ステップ(収集/前処理/分析/解釈)
・代表的な 5つの分析手法(頻度・共起・分類・感情・要約)
・AIを味方にする 分析の進め方と注意点

数字は「何が起きたか」しか教えてくれない
「離職率が15%に上がった」「売上が前月比-8%」「NPSが10ポイント下がった」——定量データは状況を映しますが、原因(=理由)までは教えてくれません。
理由は大抵、テキストデータの中にあります。
・退職者の面談記録・退職理由メモ
・アンケートの自由回答欄
・カスタマーサポートへの問い合わせログ
・営業の商談メモ・失注理由
・商品レビュー・SNS投稿
・日報・議事録・社内チャット
「数字を見て仮説を立てる」→「テキストを読んで仮説を検証する」というループが、現場で何が起きているかを深く理解する王道です。
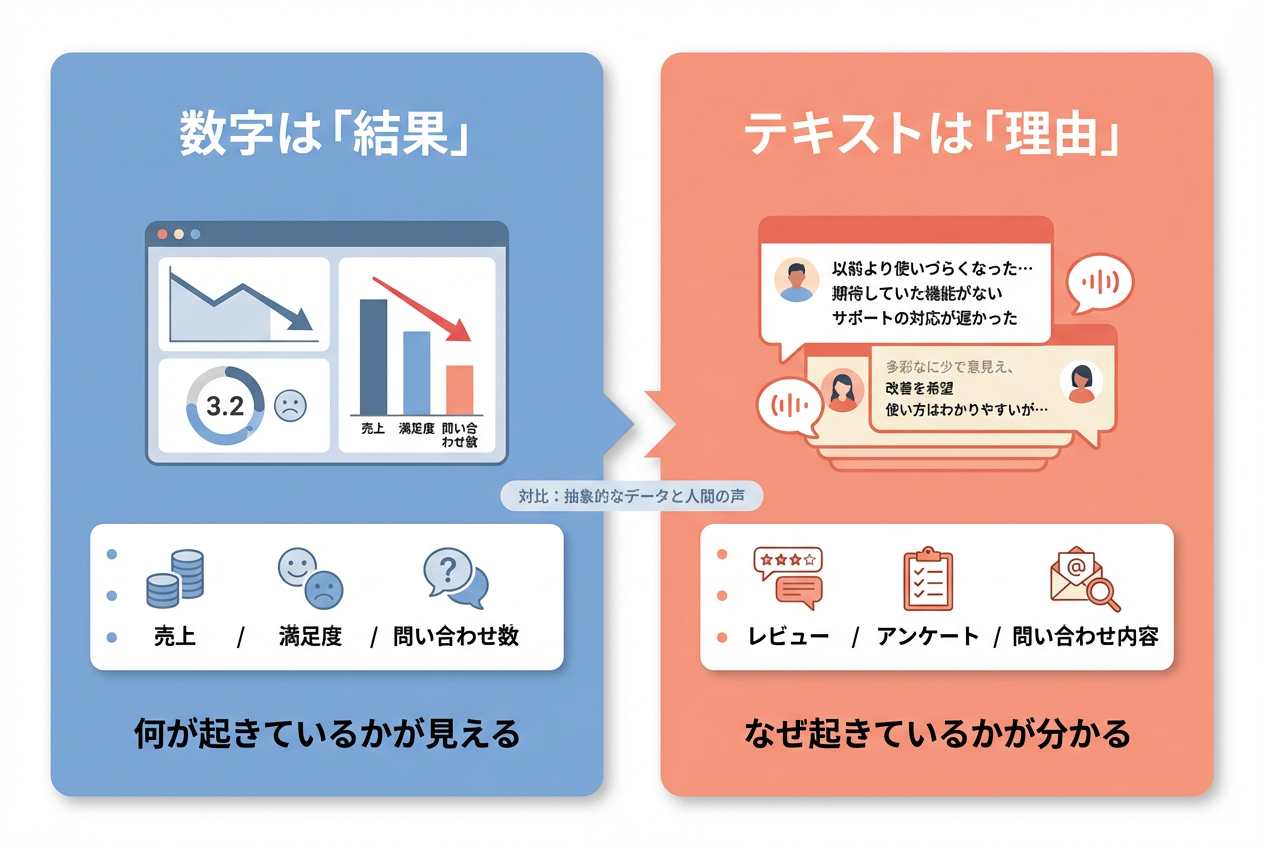
図1:数値データとテキストデータの違い
テキストデータ分析の4ステップ
| ステップ | やること | ツールの例 |
|---|---|---|
| ① 収集 | アンケート回答、問い合わせログ等を集める | Googleフォーム、CRM、社内DB |
| ② 前処理 | 表記統一、個人情報マスク、重複除去 | Excel、Python、Power Query |
| ③ 分析 | 頻度・共起・分類・感情・要約を算出 | ChatGPT、Claude、KH Coder |
| ④ 解釈 | 気づきを引き出し、次のアクションを決める | 人間の判断+AIの壁打ち |
重要なのは、①〜③はAIに任せて、④に人間の時間を使うことです。現場の文脈・事業の経緯を知っているからこそできる解釈が、最終的な価値を決めます。
代表的な5つの分析手法
① 頻度分析
出現する語の頻度を数える最もシンプルな方法。「どの言葉がよく出るか」を把握します。たとえば退職理由の自由回答から「人間関係」「労働時間」「評価」といった頻出語を抽出すれば、主要な不満テーマが見えます。
② 共起分析
一緒に出てくる語の組み合わせを分析する方法。「人間関係」と「上司」が高頻度で共起していれば、問題の原因がより特定できます。ネットワーク図で可視化すると、問題構造が一目瞭然です。
③ 分類(テーマ抽出)
文章をカテゴリに仕分けする方法。アンケートの1,000件の自由回答を「価格」「品質」「サポート」「デザイン」等のテーマに分類すれば、どこに改善リソースを集中すべきかが見えます。AIはこの分類を数分で実行できます。
④ 感情分析
ポジティブ/ネガティブ/中立の感情極性を判定する方法。SNSや商品レビューの大量データから「この機能を批判している声の割合」を定量化できます。
⑤ 要約
大量のテキストを要点のみに圧縮する方法。100件のインタビュー記録を10個のキーメッセージに要約する、といった使い方が有効です。AIが最も得意とする領域の一つです。
AIを使うテキスト分析の流れ(実例)
たとえば「顧客アンケートの自由回答500件」を分析する場合、次のようにAIを使います。
以下の500件の自由回答を分析してください。
・頻出の不満テーマを5〜7個に分類
・各テーマの件数と代表的な回答例を3つずつ
・改善優先度を「件数×インパクト」の2軸で評価
・改善アクション候補を3つ提案
回答データ:
[自由回答を貼り付け]ChatGPT/Claude/Geminiのいずれも、このレベルの分析を数分でこなします。重要なのは 出力のテンプレートを指示に埋め込む こと。テーマ数・回答例数・評価軸を固定すると、結果を使いやすい形で受け取れます。
使うツールの選び方
| ツール | 向いているケース | 特徴 |
|---|---|---|
| ChatGPT/Claude/Gemini | 〜1,000件程度の自由記述 | 対話しながら切り口を変えられる |
| KH Coder(フリー) | 学術・定性調査での頻度・共起分析 | 日本語形態素解析に強い、統計的検定も可 |
| Microsoft 365 Copilot Analyst | Excel/CSV上のデータに対する分析 | ブック内データを直接要約・分類 |
| Python(pandas + MeCab等) | 数万〜数十万件の大量データ | 再現性・自動化が容易 |
| BI+テキスト分析プラグイン | 継続的なダッシュボード化 | Tableau/Power BI等と連携 |
テキストデータ分析で陥りやすい3つの落とし穴
落とし穴1:感覚で結論を出してしまう
→ 「印象的な1件」に引きずられないよう、必ず件数(頻度)を併記。1件の強い批判と、100件の弱い共感は、どちらも重要です。
落とし穴2:前処理を軽視する
→ 半角・全角、表記ゆれ、個人情報のマスクを怠ると、後の分析精度が大きく落ちる。「入口の品質」が分析全体を決めます。
落とし穴3:AIの解釈を検証しない
→ AIが「これが主因です」と言っても、必ず元データで裏取り。5件ほど該当回答を目で確認するだけでも、精度のズレはすぐ見つかります。
よくある質問(FAQ)
Q1. 何件から分析を始めるべき?
目的次第ですが、感覚的な傾向を掴むなら30件、統計的に有意な分類をしたいなら100件以上 が目安です。少量でも、AIは「分類の切り口」のアイデア出しには有用です。
Q2. 無料版のChatGPTに自由回答を貼っても安全?
個人情報や機密情報を含む場合は危険です。社外AIの無料版は入力が学習に使われる可能性があるため、ChatGPT Team/Enterprise、Claude for Work、Microsoft 365 Copilot等の学習されない契約を使うか、個人情報を事前にマスクしてください。
Q3. 分析結果をレポートにするときのコツは?
「頻度上位5テーマ → 各テーマの代表引用3件 → 改善仮説 → 次アクション」の順に並べるのが最も伝わりやすい構成です。引用をそのまま掲載すると、読み手が納得しやすくなります。
シリーズで扱う内容
本シリーズでは、実際の業務シーンごとにテキスト分析の活かし方を解説します。
・第2回:アンケートの自由回答から”本当の改善点”を見つけた話
・第3回:商品レビューから”売れなかった本当の理由”が分かった話
・第4回:日報を分析したら”忙しさの正体”が見えてきた話
・第5回:問い合わせを整理したら”同じ問題が繰り返される理由”が分かった話
・第6回:テキストデータ分析を”仕事に定着させる”ための考え方
まとめ:数字の次に「テキスト」を読むクセをつける
・数字は「何が起きたか」、テキストは「なぜ起きたか」を教えてくれる
・4ステップ(収集/前処理/分析/解釈)で全体像を押さえる
・5手法(頻度・共起・分類・感情・要約)でテキストを料理する
・AIは①〜③を、人間は④を担う役割分担が鉄則

次回予告
次回(第2回)は、実例として「アンケートの自由回答から本当の改善点を見つけた話」を、AIを使った具体手順で解説します。
<文/岡崎 凌>



新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →