「スモールデータじゃダメなんですか?」市場調査・マーケティングリサーチの専門家に聞いてみた
公開日
2017年3月1日
更新日
2026年7月26日

この記事のポイント
・スモールデータ(小規模データ)は「使えない」と誤解されがちが、現場では十分使える
・ビッグデータ(大規模データ)とスモールデータの適用シーンは明確に違う
・小規模データは「仮説検証・原因探索・個別人間息」に強い
・大データ/小データの選び方を代表例とともに表で整理

「ビッグデータ」がもてはやされ、企業の販促や広告宣伝、マーケティング関連の部門で「うちもビッグデータを使わないと…」「大量にあるデータをお金に変えなくては…」という焦りを抱えているところは少なくありません。でも、ビッグデータって使わないといけないものなのでしょうか。
今回、市場調査・マーケティングリサーチ分野の最大手、株式会社インテージのMCA事業本部執行役員本部長 長崎貴裕さんに、スモールデータを活用する意味や、スモールデータでできることをお聞きしました。
スモールデータとビッグデータとの違い
ーーそもそもどこまでが「スモールデータ」で、どこからが「ビッグデータ」かという問題もあると思うのですが、その違いをどのように捉えていますか?
実は、当社では「スモールデータ」「ビッグデータ」という捉え方はあまりしていません。ただ、それに近い区分として「集めるデータ」と「集まるデータ」という言い方をしています。
「集めるデータ」というのは、分かりやすく言うとアンケート調査ですね。アンケートも、理屈の上では1万人とか10万人という単位で取ることはできますので、そこまでのデータ量になるともはや「ビッグデータ」と呼ぶべきなのかもしれませんが、私たちの中では「集めるデータ」は相対的に「スモールデータ」という扱いです。
一方で、例えばお店のレジから上がってくるPOSデータのように、売上を自動的に集計しているようなものや、Webサイトなどのアクセスログ、ユーザー行動ログのような、「自然にどんどん集まってくる」データを「集まるデータ」と捉えています。こちらがいわゆる「ビッグデータ」のイメージです。

ーーデータの収集の仕方で分けられているということですが、「集めるデータ」と「集まるデータ」にはどんな違いがあるのでしょうか。
「集めるデータ」のほうは、データを取る目的があって、そのために収集するデータと言えます。「集まるデータ」のほうは、データを取ることが主目的ではなく、何か別に、ビジネス上の必要性があって、その流れの中で「取れちゃう」データ、ということになります。
「集めるデータ」の一番の利点は、調査する人の目的や知りたいことに応じて、必要なことを聞けるということですね。先ほど「10万人を対象にアンケートを実施できる」と言いましたが、現実的には調査にコストがかかるので、サンプル数は数百からせいぜい数千という数字になるのが通常です。データ数は少ないですが、聞きたいことを聞けるので、データを取った後の使い勝手が良いのが特徴です。
「集まるデータ」のほうは、必ずしも目的に応じた活用ができるかというとそうでもない。むしろ、「こんなデータが取れたけど、何の目的に使えるかな」という考え方になります。ここ数年は特に、「ビッグデータは素晴らしいもの」と思われがちですが、ビッグデータは往々にして何らかのクセを持っています。特に一企業が持っているビッグデータは、何らかの前提条件に左右されたデータなので、そのままきれいに活用できるかというと、意外に難しいものなのです。
スモールデータは正しいの?
ーーアンケートの場合はサンプル数が数百から数千というお話でした。感覚的には、ビッグデータのほうが、より知りたい対象の「全体」を正しく反映しているように思えます。スモールデータで、正しく「全体」の意見や状況などを把握することはできるのでしょうか。
確かにデータ数が少ないことで、「全体」との誤差が生じるということはありますね。「サンプルを抽出して得たデータ」と「全体」が完全一致となることはありませんから、誤差についてはどこまで許容するか、という話になります。
まず、純粋に統計学的な話をすると、サンプル調査の場合「標準誤差」というものがあります。母集団からある数のサンプルを無作為に選ぶとき、選ぶサンプルの組み合わせによってばらつきが生じますが、統計データがどの程度ばらつくかを、すべての組み合わせについての標準偏差で表したものを「標準誤差」と言います。
例えば「比率の標準誤差(σp)」は、このように式で表すことができます。
σp = 2√( P(1−P) ÷ n )
(P:比率 n:サンプル数 ※「2」は信頼度95%の係数1.96の近似値)
ただ、この式だと一般の人には意味が分かりにくいので、私たちは通常こういう誤差表をお客さまに見せながら、「サンプル数によって、回答にこのくらいの誤差が生じます」という話をします。
サンプル数と回答比率の誤差表
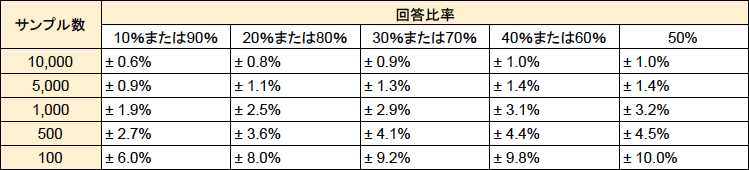
表を見ていただくと分かるように、サンプル数が少なくなると誤差は大きくなります。
例えば、サンプル数が500で、「Aという製品を使ったことがある」という回答の比率が20%だったとすると、そこには±3.6%の誤差があり、製品Aの本当の使用率は「16.4%〜23.6%」の間にある確率が高い、という意味になります。
統計データとして出てくるこの振れ幅を、大きいと見るか小さいと見るかはデータを使う人次第ですが、回答比率は調査をしてみるまで分かりませんので、より誤差を小さくしよう、つまり「全体を正しく反映したデータを得よう」とするなら、サンプル数を増やして調査を実施するということになります。
サンプル調査において、抽出したサンプルが調べたい対象の全体(母集団)を正しく代表している「程度」のことを、統計学では「代表性」と言います。私たちはより分かりやすく「市場反映性」と言ったりしていますが、要するに、サンプルの質を母集団の質に近づけることで市場反映性を高めようとしています。サンプルの質というのは、例えば「年齢」「性別」「居住地」その他の属性の比率のことですね。それを母集団内の実際の比率に近づけるよう、サンプルの管理をしているのです。
ーー具体的にどんなことをされているのでしょうか。
ネットリサーチの場合で説明してみますね。
例えば…調べたい対象の全体(母集団)が日本在住者だとしましょうか。
普通、私たちも含めネットリサーチを行う会社は、モニターを集めて数百万人という単位で確保しています。
ネットリサーチのモニターは、まず「インターネット利用者」という属性にあることは間違いありません。一昔前は、この「インターネット利用者」という時点でバイアスがかかっているとされていました。でも今はインターネットが広く普及して、10代〜50代くらいまではだいたいネットを使っています。だから、母集団と「インターネット利用者」はだいたい質も同じだろうという見方をしています。
では、「インターネット利用者」のうち、「ネットリサーチ会社にモニターとして登録する人」はどう見るべきでしょうか。実はこのグループは、結構いろんなクセを持っています。今は女性のほうが男性よりもかなり多かったりしますね。他の属性においても偏りがあります。ただ、あくまでサンプルの「候補」なので、一旦登録してもらって、さまざまな属性を調査して、情報として蓄積しておきます。
その上で、実際に「サンプル数1000人で調査しよう」となった時に、抽出する調査依頼対象者の質を、全体に近くなるようにして調整しているんですね。

ーーでも、その抽出するサンプルの質が母集団に近いかどうかは、どうやって確かめているのでしょうか。
そうですね、ここがなかなか難しい話なのですが、一応、国勢調査が日本在住者に対する調査として一番規模の大きなものなので、これを正しいものとして受け入れています。そのほかにも、総務省で行っているさまざまな調査や、世論調査なども検証の材料としています。
ただ、近年はそうした大きな調査も、回収率が下がってきているんですね。国勢調査は、前々回の2012年の調査の時から全体の回収率を発表していませんが、おそらくかなり回収率が下がっているのではないかと想像します。また、回収できても回答が満足にされていないケースも少なくないようです。
世論調査の砦だったRDD(Random digit dialing)方式、いわゆる電話調査も、データが少し怪しくなってきています。昨年から、世論調査の対象の下限年齢が「20歳以上」から「18歳以上」に引き下げられました。これは、「選挙権がある人の意見を世論と呼ぶ」という世論調査の基本的な考えがあるためです。
今までも、固定電話に電話をかけた時の回答率が低いことは問題になりつつあったのですが、この下限年齢を引き下げた時に、さらにその問題が大きく露呈したのです。そこで今は、固定電話と携帯電話の両方にかけるハイブリッド型の世論調査が行われているんですけれども、固定電話と携帯電話の比率を何割にするのが正しいのか、という疑問に対してだれも答えを持っていない状況です。今はなんとなく「半々にしてみました」とか「利用率に応じて変えました」ということをやっているようなのですが、実際に電話がかかって調査に協力してくれる人の割合は、その通りにならない。そのため、「統計的な正しさ」というものがほとんど説明不能な状態になっています。
ただ、これはもう、正しさを保証するというよりは、私たち自身の努力目標みたいなものなので、入手できるデータはできるだけ入手し、統計理論を元に抽出フレームを調整して、サンプルの質を母集団の質にできるだけ近づけるということを行っているわけです。
スモールデータを活かすのに必要な知識とは

ーー企業のマーケティング部門の方が、スモールデータを上手に活用するには、どのような知識が必要でしょうか。
これは、私たちにも同様に言えることですが、数字に対する「センス」は必要だと思います。実際に調査をすると、スモールデータとは言っても、かなりの量のアウトプット・集計ができるので、その中から何が「意味のある違い(有意差)」なのかを見極められる力があるとよいですね。
そのためには、調査結果として手にした数字を「そうなのね」と素直に納得してしまうのではなく、その数字にどういう意味があるのかを常に考えたり、気になる「違い」があればなぜその「違い」が出たのかを考えるようにすると、センスが磨かれると思います。
また、基本的な「多変量解析」「因子分析」「重回帰分析」といった分析手法がどういうものなのかを理解しておくと、数字を見た時にその数字が意味することが分かり、判断を助けることになるでしょう。統計手法や分析手法については、いろいろなものが新しく出てきてもいますので、そういうものを自分で調べて吸収していけると、なおよいですね。
あとは、調査をする、データを集める目的を常に見失わないことも大切です。結局、企業の何らかの課題解決やビジネス判断につながらなければ、その調査がどんなに正しくても意味がありません。「この質問への回答がどうだったら、どんな判断を下すのか」ということを常に念頭に置いて調査設計をすることが、スモールデータを余すところなく活用するためのポイントだと思います。
<こっそり知りたいマーケティングリサーチのツボ!>
インテージでは、マーケティングリサーチに関する素朴なギモンや、落とし穴、最新トレンドを学べるまんがを公開しています。企業のマーケティング担当者など、リサーチに携わる人はぜひ一読を!
|
和から株式会社 鈴木のコメント: ビッグデータとスモールデータという比較を「主体的に集めるデータ」と「副産物として集まるデータ」という観点からお話しいただきました。スモールデータの扱いについては、データを集める目的を忘れずに、統計理論に基づいていかに意味のある結果を出すかが重要になってくるとのことでした。 弊社の統計学研修でも、算数の学び直し、特に「比」や「割合」に対する「数字センス」を磨くことにより、受講者の方に統計学をさらにうまく活用していただけるよう心がけています。 ビッグデータかスモールデータかではなく、まずは、データに対してどういう風に向き合っていくのかが大切です。「統計学=万能なもの・すごいもの」として「数字に操られる」のではなく、上手にデータを分析する能力を身につけたいものですね。 |
(取材協力=株式会社インテージ/文・写真=畑邊康浩)
ビッグデータ vs スモールデータ 比較表
| 視点 | ビッグデータ | スモールデータ |
|---|---|---|
| サンプル数 | 数十万~数億件 | 数件~数千件 |
| 代表ツール | SQL・BIツール・機械学習 | インタビュー・試験・人間の目 |
| 得意 | パターン検出・予測・自動化 | 仮説検証・原因探索・人間息理解 |
| 不得意 | コンテクスト理解・個別事情 | 全体傾向・長期予測 |
| 適用例 | EC購買履歴分析・ログ解析 | 顧客インタビュー・A/Bテスト・口コミ分析 |



新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →