Excel業務が変わる!Copilot×Python自動化術-第3回:数字に“意味”を見つける分析思考
公開日
2026年2月21日
更新日
2026年5月6日

この記事の主な内容
この記事のポイント
・数字を集計するだけで終わらず、“意味”を取り出す分析思考の型
・CopilotとPython in Excelで使える 4つの分析視点(比較・構成・推移・外れ値)
・そのまま使える 分析プロンプト例5つ
・AIに任せる部分/人間が判断する部分の線引き

集計と「分析」は違う
月次レポートで「売上:1,234万円」と書くのは集計です。
分析は、「昨年比+8%、しかし主要3商品中2商品は減少。伸びているのはAの新規客獲得分」のように、数字に”意味”を見つけること。集計で終わる報告書から、分析を付けた報告書に変わると、会議の議論も意思決定の速度も変わります。
AIは集計を速くしてくれますが、単に数字を出すだけでは「分析」にはなりません。分析思考の型をこちら側が持ち、AIを使い倒すことが大事です。
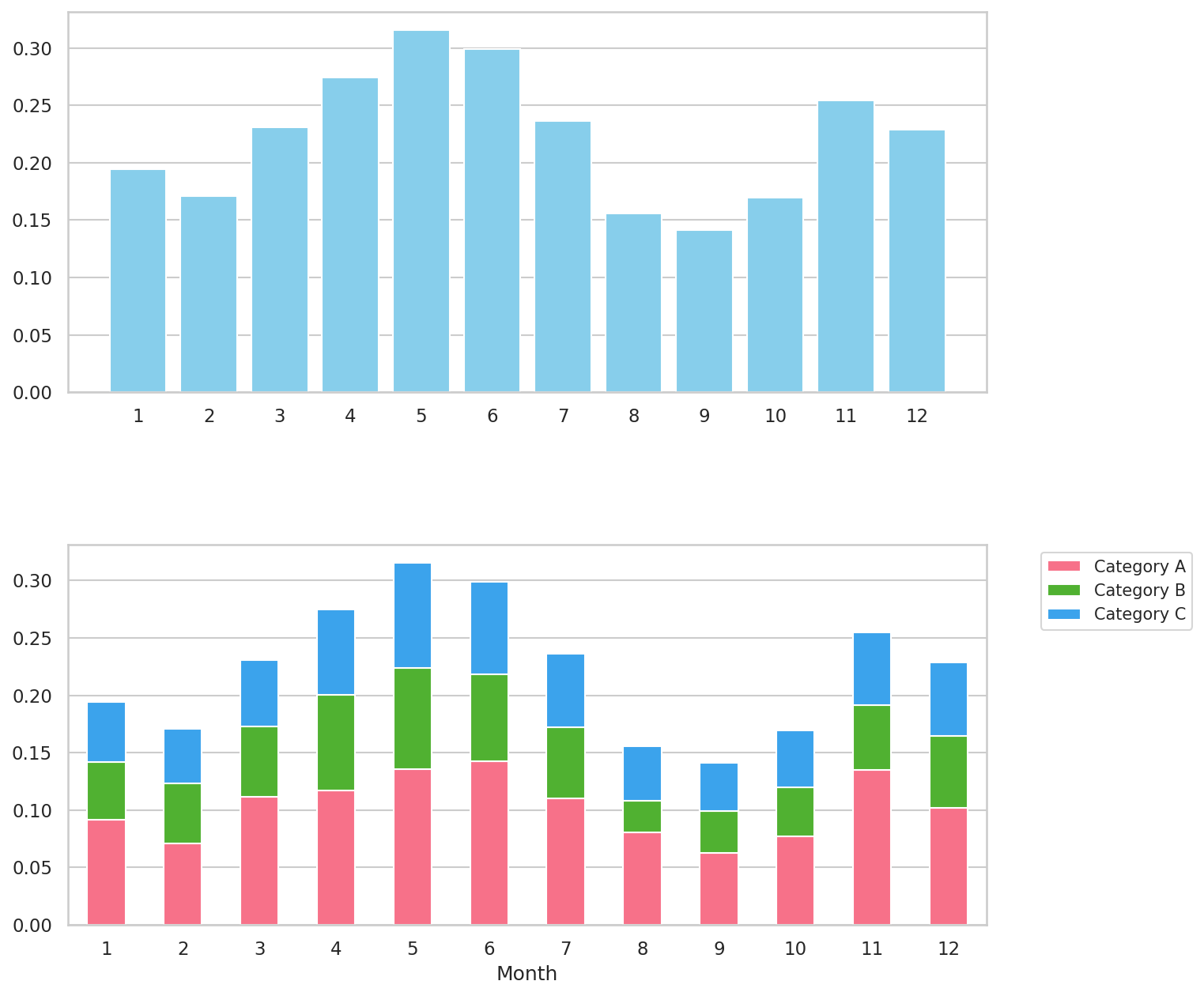
図1:生成AIで作成した月別棒グラフとカテゴリ内訳付きの積み上げ棒グラフ
数字に意味を見つける「4つの視点」
どんな数字も、この4つの視点で眺めるだけで解釈が進みます。
| 視点 | 問い | よく使う可視化 |
|---|---|---|
| ① 比較 | 「他と比べてどうか」 | 棒グラフ、前月比、競合比 |
| ② 構成 | 「何が全体を占めているか」 | 積み上げ棒、円グラフ、パレート図 |
| ③ 推移 | 「時間で変わったか」 | 折れ線、移動平均、累積 |
| ④ 外れ値 | 「異常に大きい/小さい点はどこか」 | 散布図、ヒストグラム、箱ひげ図 |
AIに指示する時は、この4つのどの視点でデータを見てほしいかを明記するのがコツです。
分析プロンプト例 5つ
① 比較の視点
売上データ(A列:日付、B列:商品、C列:金額)があります。
以下の比較を行ってください。
・商品別の今月合計と前月合計
・前月比の差分(金額・%)
・前月比が-20%以下、または+30%以上の商品をハイライト
結果は表にしてコメント欄に1行「最も注目すべき変化」を1つ書いてください。② 構成の視点
顧客別売上データから、以下の構成分析をお願いします。
・売上上位20%の顧客が全体の何%を占めるか(80/20ルール)
・上位5社/中位10社/下位の合計で3分類
・円グラフで可視化
「集中度が高い/分散している」のどちらかの結論を1文で添えてください。③ 推移の視点
過去12ヶ月の売上推移データがあります。
・月次データに3ヶ月移動平均を追加
・前年同月比の折れ線を重ねて表示
・「トレンドとして上昇/横ばい/下降」のどれかを判定し、根拠となる数字を添えてください
グラフと判定コメントをセットで出力。④ 外れ値の視点
注文データから、以下の外れ値検出を行ってください。
・金額の平均から±3σ外れる取引
・1顧客1日に5件以上の注文
・土日祝日の高額取引(平日平均の5倍以上)
各外れ値について、原因候補を3つ挙げてください(例:記入ミス、特別注文、不正等)。⑤ 複合分析
以下のデータで「売上が減った本当の理由」を探ってください。
・月別売上、商品別売上、顧客別売上、地域別売上を全て参照
・減少額の大きい順に要因を分解(要因分解表)
・「新規客減少/既存客離脱/単価低下/数量減少」のどれが主因か
結論を3行で示し、根拠データを併記してください。Python in Excel が強い分析シーン
図2:生成AI×Pythonによるデータの可視化
Copilotでカバーしきれない高度な分析は、Python in Excel(Microsoft 365 Business/Enterprise で2024年9月16日 一般提供開始)のほうが得意です。デフォルトで pandas・NumPy・Matplotlib・seaborn・statsmodels が import 済みで、次のような処理が数行で書けます。
| 分析 | Excel標準で難しい点 | Pythonなら |
|---|---|---|
| 相関分析 | CORREL関数を列ごとに手動実行 | df.corr()で一発 |
| クラスタリング | 不可 | scikit-learn(追加import可)で実行 |
| 回帰分析 | 「分析ツール」オプション必要 | statsmodelsのols()で標準装備 |
| ヒストグラム+外れ値 | 散布図+条件付き書式を組み合わせ | matplotlib/seabornで統合可視化 |
Python in Excel で書く散布図+回帰線の例
=PY(
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = xl("Sheet1!A1:C200", headers=True)
fig, ax = plt.subplots(figsize=(8,5))
sns.regplot(x="price", y="units_sold", data=df, ax=ax)
ax.set_title("価格と販売数の関係")
fig
)AIに任せる分析 vs 人間が判断する分析
| 工程 | 担当 | 理由 |
|---|---|---|
| データ集計 | AI | 機械的反復が得意 |
| 可視化案の提示 | AI | 候補を素早く出せる |
| 数字の解釈 | 人間 | 文脈・経緯を知る必要あり |
| 原因仮説の検証 | 協業 | AIが候補、人間が検証 |
| 次のアクション決定 | 人間 | 判断責任が必要 |
特に数字の解釈は、自社の過去の経緯・現場の事情・顧客心理を知っている人間の領域です。AIにはそれができません。分析の主役は人間で、AIは下ごしらえ担当、という関係を崩さないことが失敗を減らすコツです。
よくあるつまずきと対処
つまずき1:AIが「それっぽい分析」を出してきて、正しいかわからない
→ 毎回「根拠となる数字を添えて」と指示する。数字と結論がセットで初めて分析。
つまずき2:可視化がキレイすぎて本質を隠している
→ 必ず「もう1パターン違う視点で可視化して」と追加指示。1つの可視化だけで意思決定しない。
つまずき3:結論がふわっとしている
→ 「3行の結論」「具体数字で裏付け」を指定する。曖昧なものは再生成を指示。
よくある質問(FAQ)
Q1. CopilotとChatGPTを分析で使い分ける基準は?
データが既にExcelにある → Copilot in Excel(コピペ不要)。
複数ソースのデータやWeb上の情報を横断 → ChatGPT/Claude。
大量行・統計処理 → Python in Excel。
使い分けの基準は「どこにデータがあるか」と「処理の複雑度」です。
Q2. 分析結果をレポートにするときのテンプレは?
「サマリー3行 → 1つの主要グラフ → 根拠データ表 → 次アクション3つ」のフォーマットが最も伝わりやすいです。Copilotに「この構成でレポートを作って」と指示すると一気に整います。
Q3. 異常値が出たとき、どこまで深掘りすべき?
金額のインパクトで決めます。上位3件の異常値が全体の5%以上占めるなら必ず原因特定。それ以下なら記録のみ残して次月に流す、という運用が現実的です。
まとめ:分析は「集計+解釈」で完成する
・4視点(比較・構成・推移・外れ値)を意識してAIに指示する
・プロンプトには根拠数字・結論文・判定コメントの3点セットを依頼
・Python in Excelで相関・回帰・クラスタリング等の一段深い分析
・解釈と意思決定は人間の仕事、AIは下ごしらえ担当

次回予告
次回(第4回)は「ぐちゃぐちゃなデータも一発で整理」をテーマに、データクレンジングの実践手順を解説します。
参考:
・Microsoft「Python in Excel availability」公式ドキュメント(2024年9月16日 一般提供開始)
・Microsoft「Excel で Copilot を使用して数値データに関する分析情報を取得する」公式ドキュメント
<文/岡崎 凌>



新着記事


同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →