仕事の判断が変わる 機械学習のキホン-第1回:“おすすめ”の正体は判断の肩代わり!購買・行動データでレコメンドがわかる【機械学習をやさしく解説】
公開日
2026年1月18日
更新日
2026年4月22日

「機械学習」と聞くと、多くの人は高度な分析や、未来をズバリ当てる予測を想像しがちです。
ですが、実際に仕事の現場で価値を生んでいる使い方は、もっと地道なものであり、もっと実用的なものです。
人が毎回悩んで決めている判断の一部を、迷わず任せられる状態にする。
レコメンド(おすすめ表示)は、その代表例です。
そこで今回は、教科書に登場するようなモデル名や数式の話はいったん置いておいて、
どんなデータを使って、どんな判断を、どこまで任せられるのかを、実務のケースを通して考えてみましょう。

この記事の主な内容
ケース:EC運営担当Aさんの“終わらない悩み”
Aさんは自社ECサイトの運営担当。商品数はおよそ300点で、新商品も定期的に追加されます。
Aさんの仕事のひとつが、サイト上の「おすすめ欄」や、メルマガ、アプリ通知に表示する内容を決めることです。
ここで、Aさんは毎回同じことで悩みます。
・誰に、何を見せる(勧める)べきか?
・おすすめ枠は限られている。どれを優先する?
・無難にすると、結局いつも同じ商品になってしまう
もちろん、Aさんは適当に決めているわけではありません。
購入履歴をExcelで確認し、最近よく見られている商品をチェックし、在庫状況も考慮します。
ただ、そのたびに感じます。
この判断、毎回ゼロから考えるほど“オリジナル”な仕事だろうか?
実際には、似たような判断を何十回、何百回と繰り返しているだけではないでしょうか。
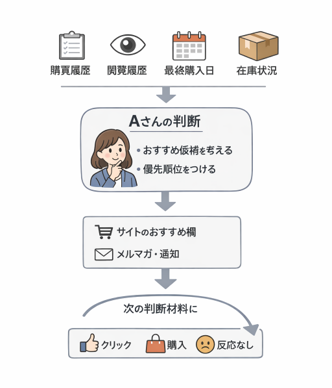
【図1:Aさんの意思決定フロー図】
入力:購買履歴/閲覧履歴/最終購入日/在庫など
判断:おすすめ候補を選ぶ → 優先順位を付ける → 表示・配信
結果:クリック/購入/反応なし(次の判断材料になる)
人が判断している中身をデータに翻訳すると、驚くほど単純になる
Aさんが頭の中でやっていることを分解してみます。
実は、判断材料はそれほど多くありません。
・過去に何を買ったか(購買履歴)
・最後に購入したのはいつか(購入間隔)
・最近どの商品ページを見ているか(閲覧履歴)
ここで大事なのは、これらが特別なデータではなく、
多くの会社ですでにどこかに保存されている情報だという点です。
これらのデータを並べてみると、次のような偏りが見えてきます。
・商品AとBを買った人は、その後Cを買うことが多い
・特定カテゴリをよく見ている人は、関連商品を選びやすい
レコメンドは、この偏りを使って、
「この人には、まずこれを見せておこう」という順番を作ります。
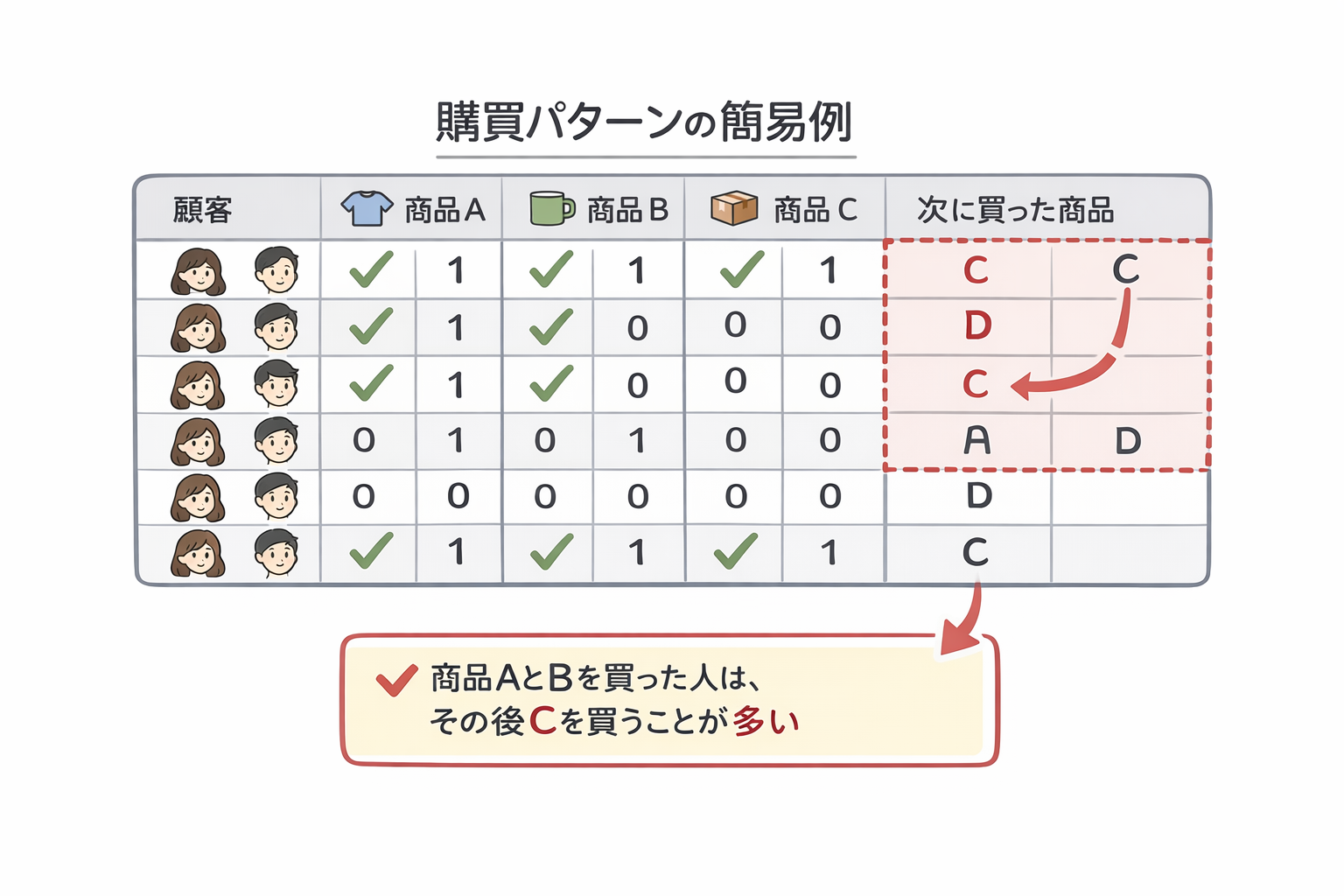
【図2:購買パターンの簡易例(表)】
行:顧客(例:10名)
列:商品A/B/Cの購入有無(0/1)+次に買った商品
ポイント:AとBを買った人の次はCが多い、などの偏り
レコメンドは未来を当てる魔法ではなく、選択肢の並べ替え
レコメンドというと、未来をズバリ当てる技術だと思われがちです。
ですが、仕事で本当に価値があるのは、そこではありません。
完璧な正解を当てることより、失敗しにくい順に並べること。
現場では、「これが唯一の正解」という状況はほとんどありません。
ある程度妥当な候補が上に並んでいれば十分です。
候補が整理されていれば、人は
「変なものが混ざっていないか」を確認するだけで済みます。
導入して何が変わった?Aさんのチームで起きた現実的な変化
Aさんのチームでは、すべてを自動化するのではなく、
まずはおすすめ候補の一部だけをレコメンドに任せてみました。
・候補が最初から並ぶので、作業が「考える」から「選ぶ」に変わった
・経験の浅いメンバーでも、同じ基準で判断できるようになった
・なぜその商品を出したか、後から説明しやすくなった
必ずしも売上が劇的に伸びたわけではありません。
それでも、判断にかかる時間が減り、迷いが減り、改善を続けるための振り返りができるようになりました。
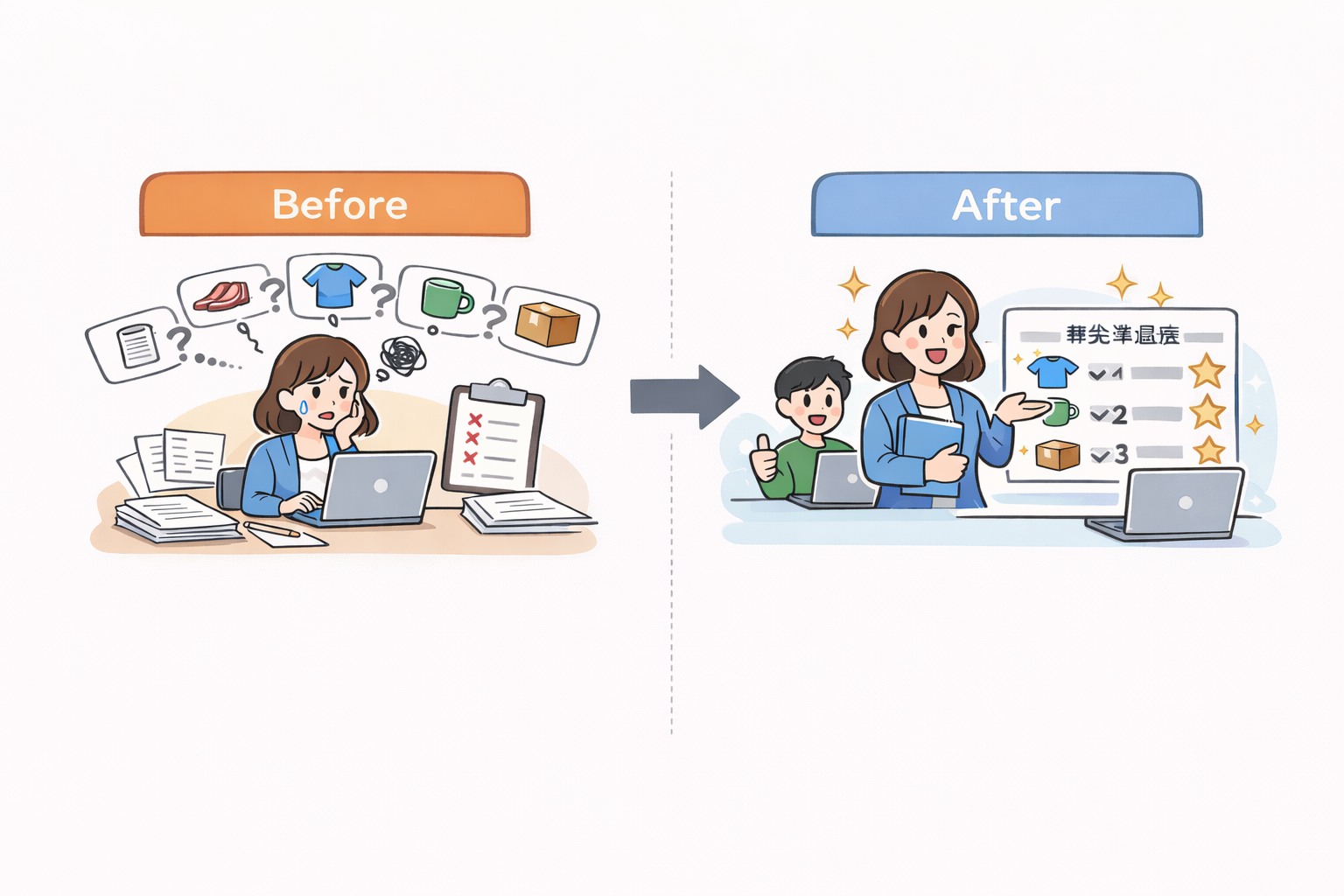
【図3:機械学習モデルによるレコメンドを取り入れた結果】
Before:人が毎回候補出し、判断が属人化
After:仕組みが候補提示、人は確認と最終判断
機械学習に任せやすい判断/任せにくい判断
任せやすい判断
・正解が1つに決まらない
・同じ判断を何度も繰り返している
・過去データが十分に残っている
任せにくい判断
・前例が少ない、新しいケース
・毎回条件が大きく変わる
・責任や影響が大きく、最終判断が必要なもの
よくある失敗:最初から全部任せようとする
レコメンド導入でよくある失敗は、最初からすべてを自動化しようとすることです。
1)候補出しだけ任せる
2)効果を見ながら範囲を広げる
3)例外や責任が重い部分は人が判断する
まずは、判断を少し軽くするところから始める。
これが現場で失敗しにくいやり方です。
今日からできる一歩
チェック1:繰り返している判断はある?
・誰に何を案内するか
・どれを優先するか
チェック2:その判断の材料になる過去データは残っている?
購買履歴/閲覧履歴/対応履歴など
チェック3:まずは候補出しだけ任せられない?
全部任せる前に、人が確認できる形にできないか

まとめ
レコメンドは、便利な表示機能ではありません。
人が毎回悩んで決めている判断を、データで再利用できる形にする仕組みです。
・購買や行動データを使う
・完璧を目指さず、失敗しにくい順に並べる
・まずは候補出しから任せる
この考え方がつかめると、機械学習は
「難しい技術」ではなく、今ある仕事の手間を軽くする道具として見えてきます。
次回は、文章データ(問い合わせやアンケート)を使って、
判断コストをどう減らせるかを見ていきます。
<文/岡崎 凌>


新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →