標本調査と実験のキホン-第2回:サンプリング方法と“偏り”の落とし穴【統計学をやさしく解説】
公開日
2025年10月30日
更新日
2026年4月23日
この記事の主な内容
はじめに

第1回では「母集団」と「標本」の関係を学びました。全体(母集団)をすべて調べるのは現実的ではないので、その一部(標本)から全体を推測する──これが統計の基本です。
では、どうやって「その一部」を選ぶのか?
この選び方こそがサンプリングであり、統計分析の信頼性を左右する最重要ポイントです。
「ランダムに選んだから大丈夫」と思っても、実はそこに“偏り(バイアス)”が潜んでいることがあります。
今回は、サンプリングの代表的な方法と偏りの防ぎ方を、ビジネス初心者にもわかるようにやさしく、かつ詳しく解説します。
1. サンプリングとは?──データを「代表」にする技術
サンプリングとは、母集団から一部のデータを選び出すことです。たとえば「全社員の平均残業時間」を知りたいとき、全員に聞くのは大変ですよね。代わりに100人を選んで調査し、その結果を全体に当てはめるのがサンプリングの考え方です。
ポイントは、この「選び方」で結果がまるで変わるということです。偏った取り方をすると、どんなに正確に計算しても誤った結論にたどり着いてしまいます。
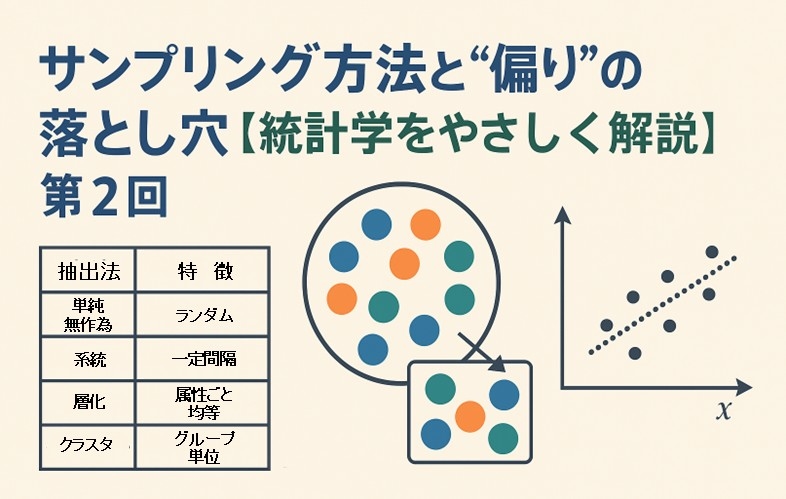
2. サンプリング方法の4つの代表例
サンプリングの方法は多くありますが、まずは基本の4つを押さえましょう。
| 抽出法 | 特徴 | 例 |
|---|---|---|
| ① 単純無作為抽出 | 完全にランダムに選ぶ | 社員番号でランダムに100人を選ぶ |
| ② 系統抽出 | 一定間隔で選ぶ | 名簿の10人ごとに1人を選ぶ |
| ③ 層化抽出 | 属性ごとに分けて均等に選ぶ | 男女比や年代ごとに同数を選ぶ |
| ④ クラスタ抽出 | グループ単位で選ぶ | 支店・学校などの単位でまとめて選ぶ |
どの方法も「コスト」「精度」「現実性」のバランスをとる工夫です。
次の図で、特に使われることが多い層化抽出をイメージしてみましょう。
層化抽出は「多様な層をまんべんなく含める」ことで、母集団をより正確に反映します。
3. “偏り”の正体:知らぬ間に入り込むバイアス
実は、偏り(バイアス)は思っている以上に簡単に入り込みます。主な種類を整理しましょう。
| バイアスの種類 | 説明 | ビジネスでの例 |
|---|---|---|
| ① 選択バイアス | 調査対象の選び方で偏る | 都心の人だけを調べて「全国の傾向」とする |
| ② 非回答バイアス | 答えない人が特定の傾向を持つ | 不満を持つ人ほどアンケートを無視する |
| ③ 自己選択バイアス | 参加者が自分で選ぶ | ネット投票や口コミサイトで意見が偏る |
特にマーケティング調査では③の自己選択バイアスが多く、熱心なファンの意見が全体を代表してしまうケースがあります。
4. 実務でのチェックポイント
偏りを防ぐために、サンプリング時は次の点を意識しましょう。
・母集団を明確に定義する(誰を全体とみなすのか)
・層化抽出などで属性のバランスを取る
・無作為抽出の仕組みを明文化する
・非回答者の傾向を把握しておく
これらを徹底することで、調査結果の信頼性が格段に高まります。
5. ChatGPTで体験するサンプリング
AIツールを使うと、サンプリングの仕組みを“体感”できます。
たとえば、Excelの顧客リストをChatGPTに読み込ませて、こう指示してみましょう:
「1000人の顧客リストからランダムに50人を抽出して」
「男女比が半々になるように20人を選んで」
このように実際に試すことで、「ランダムとは何か」「層化とは何か」が直感的に理解できます。

まとめ
・サンプリングはデータ分析の“入口”であり、最も重要なステップ
・方法を選ぶだけでなく、偏り(バイアス)を理解して防ぐ
・層化抽出などで代表性を確保することで、信頼できる結果につながる
・ChatGPTなどのAIを使って、実際にサンプリングを試してみよう
次回は「観察研究と実験研究のちがいをビジネスで体感!」をテーマに、データから“因果関係”を見抜く方法を解説します。
解説動画


新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →