信頼区間の意味|「95%」が示すものと示さないもの
公開日
2026年5月10日
更新日
2026年6月9日

「平均値の95%信頼区間は5.0±0.3」と聞いたとき、「95%という数字は何を意味しているのか」を正確に説明できますか?信頼区間は、数式を暗記するだけでは実務で使いこなしにくい統計用語の一つです。この記事では、累計3万人以上を指導してきた和からが、よくある誤解、正しい解釈、会議やレポートでの使い方まで、社会人の目線でわかりやすく解説します。読了の目安は約12分です。
この記事の主な内容
1. 信頼区間とは何か|ひとことで言うと
結論:信頼区間とは、データから推定した結果にどれくらいの「幅」や「不確かさ」があるのかを示す考え方です。95%信頼区間は、同じ調査手続きを何度も繰り返したとき、その手続きで作った区間が真の値を含む割合が約95%になるように設計されています。「真の値が95%の確率でこの範囲にある」という意味ではありません。
たとえば「日本の社会人の平均通勤時間は片道35分±3分(95%信頼区間)」と発表されたとします。このとき意味しているのは、「同じように1万人をランダムに選んで調査し、区間を作る作業を100回繰り返したら、そのうち約95個の区間が真の平均を含む」ということです。いま目の前にある1つの区間については、真の値を含むか含まないかのどちらかであり、その区間自体に95%の確率が付いているわけではありません。
少しややこしく感じるかもしれませんが、ここで大切なのは「95%」という数字を丸暗記することではありません。データには必ずゆらぎがあり、そのゆらぎをどのくらい見込んで判断するのかを理解することです。和からでは、このような統計の考え方を、身近な例や仕事の場面に置き換えながら学んでいきます。
2. 「95%が示すもの・示さないもの」の決定的な違い
2-1. ✓ 95%が示すこと(正しい解釈)
- 調査手続きの信頼性が95%程度であること
- 同じ手続きで調査を繰り返したとき、区間が真の値をカバーする長期的な頻度
- サンプル数やばらつきから計算される客観的な精度指標
2-2. ✗ 95%が示さないこと(よくある誤解)
- 「真の値がこの範囲にある確率が95%」← これは誤りです
- 「次回の観測値の95%がこの範囲に入る」← これは誤りです(予測区間との混同)
- 「95%の人が答えた内容」← これは誤りです(パーセンタイルとの混同)
この区別は、学術的な厳密さだけの話ではありません。実務でデータを解釈するとき、信頼区間を誤って理解すると、意思決定そのものを誤る可能性があります。
たとえば会議で「平均は5.0です」とだけ報告すると、聞き手はその数字を確定値のように受け取ってしまいます。一方で「平均は5.0ですが、95%信頼区間は4.7〜5.3です」と伝えると、結果の精度や判断の慎重さまで共有できます。これが、統計を実務で使ううえでの大きな価値です。
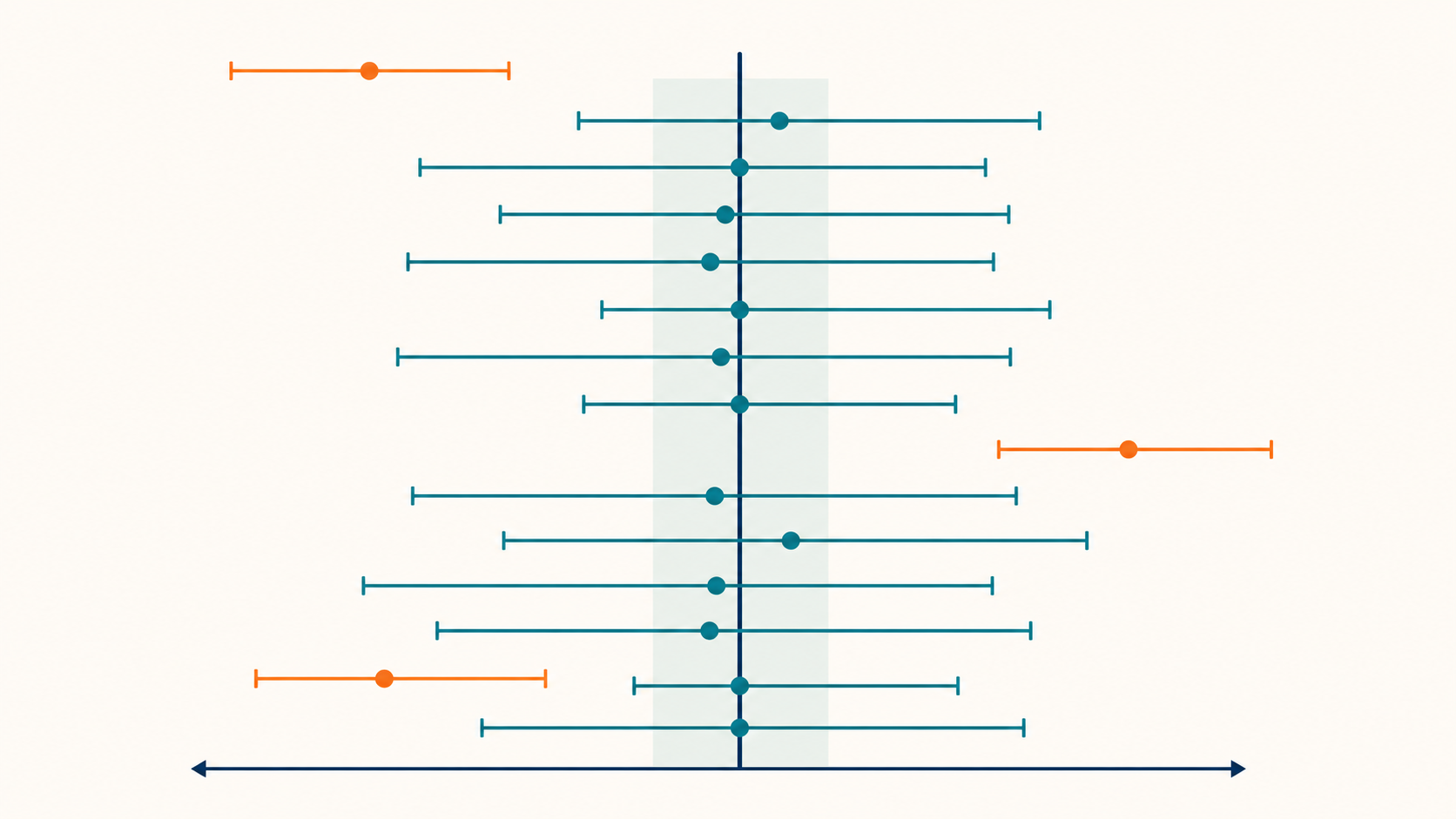
3. なぜ「真の値が95%の確率で入る」と言えないのか|頻度論の立場
古典的な統計学、特に頻度論の立場では、「真の値」は固定された定数として扱います。観測する側がその値を知らないだけで、真の値そのものが確率的に動いているわけではありません。動くのは、サンプルから計算される「区間」の方です。
和からの授業では、このような抽象的な話も、できるだけ「何が固定されていて、何が毎回変わるのか」という視点で整理します。式の前に、まずは言葉とイメージで構造をつかむことが、統計への苦手意識をやわらげる第一歩です。
たとえば日本国民の平均身長を調べたい場合、「真の平均」はその時点で1つに定まっている値です。サンプルを取り直すたびに標本平均や信頼区間は変わりますが、推定したい真の平均そのものが毎回変わるわけではありません。
3-1. ベイズ統計での「信用区間(Credible Interval)」
一方、ベイズ統計では、真の値も確率分布として扱います。この場合は、「真の値がこの範囲にある確率が95%」という表現が可能です。ただし、頻度論の信頼区間とベイズ統計の信用区間は別物です。実務でデータを発表する場合は、どちらの立場で区間を示しているのかを明確にしておくことが大切です。
4. 信頼区間の作り方|計算の流れ
母集団の平均を推定する場合、サンプル数が十分に大きいときの95%信頼区間は、次の式で近似的に計算できます。
式を見ると難しく感じるかもしれませんが、見ているポイントは大きく3つだけです。平均がいくつか、ばらつきがどれくらいか、何人分のデータがあるか。この3つがわかれば、「どのくらい幅を持たせて判断すべきか」が見えてきます。
標本平均 ± 1.96 × ( 標本標準偏差 / √サンプル数 )
ここで1.96は、標準正規分布で95%信頼水準に対応する値です。99%なら約2.58、90%なら約1.64を使います。サンプル数が小さい場合は、標準正規分布ではなくt分布の値を使うのが一般的です。
4-1. 計算例
従業員100人の年間有給休暇取得日数を調べたところ、平均12.5日、標準偏差4.0日だったとします。このときの95%信頼区間は、次のように計算できます。
12.5 ± 1.96 × ( 4.0 / √100 ) = 12.5 ± 0.78 → 95%信頼区間:[11.7日, 13.3日]
この結果は、「同じ手続きで調査と計算を繰り返すと、作られる区間のうち約95%が真の平均を含むように設計されている」と解釈します。
実務では、まず「12.5日」という点の数字だけでなく、「だいたい11.7〜13.3日の間と見ておくのが自然」と捉えると使いやすくなります。信頼区間は、数字を曖昧にするためのものではなく、判断に必要な余白を見えるようにするためのものです。
5. 信頼区間の幅を決める3つの要因
- サンプル数(n):大きいほど区間は狭くなります。幅はおおよそ√nに反比例します。
- 標本のばらつき(標準偏差):ばらつきが大きいほど区間は広くなり、推定の不確実性も大きくなります。
- 信頼水準(90%/95%/99%):信頼水準を高くするほど、より慎重な推定になるため区間は広くなります。
サンプル数を4倍にすると、信頼区間の幅はおおよそ半分になります。つまり、「推定精度を倍にしたい」場合には、「サンプル数を4倍にする」必要があります。これは、アンケート調査やA/Bテストなどでデータ収集計画を立てるときに重要な感覚です。
6. 実務での使いどころ
和からが実務でおすすめしているのは、数字を「点」だけで見せず、「幅」とセットで伝えることです。点の数字はわかりやすい一方で、過信を生みやすいものです。信頼区間を添えることで、データの強さと限界を同時に伝えられます。
6-1. A/Bテスト結果の判断
「Aパターンの方がBパターンよりCV率が5%高い」という結果が出ても、差の信頼区間が [-2%, +12%] であれば、まだ明確な結論は出せません。区間が0をまたいでいる場合は、「差があるとは言い切れない」と判断するのが基本です。
6-2. 顧客満足度調査
「満足度4.5(5段階)」とだけ示すよりも、「4.5(95%信頼区間 4.3〜4.7)」と示す方が、結果の精度やばらつきまで含めて伝えられます。
6-3. 経営指標の予測
来期売上を「100億円」と点だけで示すよりも、「100億円前後で、推定の不確実性として95億〜105億円程度の幅がある」と示す方が、リスクを含めた経営判断につながります。なお、将来の個別の値を予測する場合は、厳密には信頼区間ではなく予測区間を使う場面もあります。
7. 信頼区間を使う際の注意点
- サンプリングバイアス:標本が母集団を代表していなければ、信頼区間を計算しても意味のある推定にはなりません。
- 正規性の仮定:母集団の分布に偏りがある場合は、t分布やノンパラメトリック法の利用を検討する必要があります。
- 外れ値:少数の異常値によって、平均や標準偏差が大きく影響を受けることがあります。
- 独立性:サンプル同士が互いに関連していると、区間が不自然に狭く出ることがあり、結果を過信するリスクがあります。
和から式:信頼区間を見る前の3つの確認
- そのデータは、知りたい対象をきちんと代表しているか
- 平均だけでなく、ばらつきや外れ値も確認しているか
- その幅を見て、実務上の判断が変わるか
この3点を確認するだけでも、「計算結果を出して終わり」ではなく、「意思決定に使える統計」に近づきます。
8. 和からの統計学・データ分析教室の特徴
和からは、大人・社会人が数学・統計・データ分析を学ぶための教室です。私たちが大切にしているのは、「わからない」を否定せず、そこから一緒にほどいていくこと。信頼区間のように誤解しやすいテーマも、数式だけで押し切るのではなく、言葉・図・実務例を行き来しながら理解を深めます。
- 累計3万人以上の指導実績:30名以上のプロ講師が、目的や理解度に合わせて学習をサポートします。
- マンツーマン中心:統計検定3級〜1級、データサイエンス検定、G検定、専門統計調査士まで対応しています。
- 「なぜそうなるのか」から学べる:公式の暗記に頼らず、意味や背景を納得しながら進めます。
- 実務直結:自社データを持ち込んだ演習や、業務で使うExcel・Python・BIツールでの学習にも対応できます。
- 文系・初心者にも寄り添う設計:数式に苦手意識がある方でも、安心して学び始められます。
- 渋谷・大阪・全国オンライン対応:個人向けの学習から法人研修まで幅広く対応しています。
あなたの「わからない」から、統計学習プランを設計します
信頼区間・検定・回帰分析・業務データ分析など、今つまずいているところを一緒に整理し、目的に応じた学習ロードマップをご提案します(オンラインにも対応しています)
9. よくある質問(FAQ)
Q1. 信頼区間と予測区間の違いは何ですか?
信頼区間は、「母集団の平均などのパラメータ」を推定するための区間です。一方、予測区間は「次に観測される個別の値」を予測するための区間です。一般に、予測区間の方が信頼区間よりも幅が広くなります。たとえば、「平均年収」の信頼区間と「次に採用する人の年収」の予測区間は、まったく別のものです。
Q2. 95%・99%・90%、どれを使えばよいですか?
多くのビジネス資料や研究では、95%信頼水準がよく使われます。創薬や安全工学など、より慎重な判断が求められる場面では99%、探索的な分析や社内の初期検討では90%が使われることもあります。目的やリスクの大きさに応じて選ぶことが大切です。
Q3. 統計検定2級ではどこまで出題されますか?
母平均・母比率・母分散の信頼区間、t分布・カイ二乗分布・F分布を使った推定などが出題範囲に含まれます。和からのマンツーマンでは、現在の理解度に合わせて、必要な範囲を短期集中で整理することも可能です。
Q4. 実務で「サンプル数が少ない」と言われるのは何人未満からですか?
厳密な共通の閾値はありません。ただし実務上は、30未満ではt分布を使うかを検討し、10未満では正規性の仮定に注意し、5未満では強い結論を出さない方が無難です。サンプル数だけでなく、データのばらつきや収集方法も合わせて確認しましょう。
Q5. AIが計算してくれるので、人間が信頼区間を理解する必要はありますか?
あります。AI(ChatGPTなど)が信頼区間を計算してくれても、その結果を正しく解釈し、意思決定に使うのは人間です。AI時代こそ、「この数字は何を意味していて、何を意味していないのか」を見抜く統計リテラシーが重要になります。「95%の確率で真の値が範囲内にある」と誤解したままでは、計算精度が高くても適切な判断にはつながりません。
関連する記事・サービス


新着記事


同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →