標本調査と実験のキホン-第4回:良い実験を設計するための考え方【統計学をやさしく解説】
公開日
2025年11月1日
更新日
2026年7月10日
この記事の主な内容
はじめに
第1〜3回で、統計学の基礎である「母集団と標本」から始まり、「サンプリング」や「観察研究と実験研究の違い」までを学びました。いよいよこのシリーズの最終回では、統計学の応用の核心──良い実験の設計方法(実験計画法)をやさしく解説します。
実験は、ただ“試す”だけではなく、信頼できる結果を得るための設計が重要です。ここを理解しておくと、ビジネスの意思決定や施策の改善が格段にレベルアップします。

1. 良い実験とは?
良い実験とは、「再現性があり、信頼できる結果が出る実験」のことです。単に「試してみた」だけでは、偶然や外部要因に左右され、正しい結論を導けません。
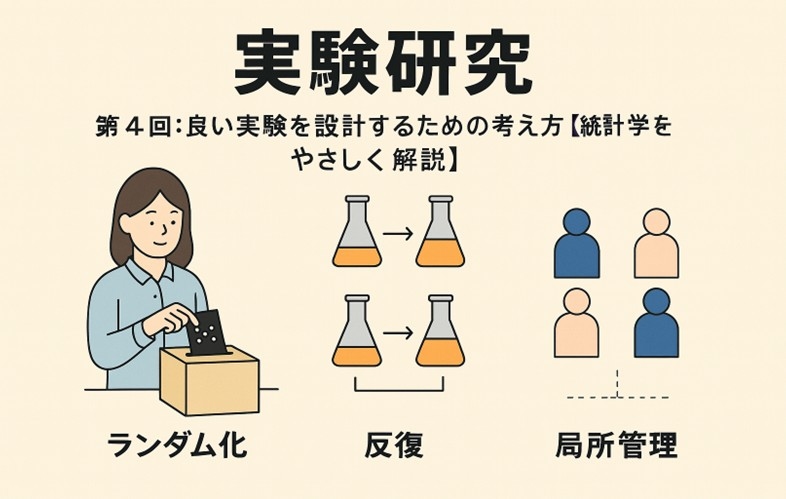
統計学の祖・フィッシャー(R.A. Fisher)は、良い実験の条件として次の3原則を提唱しました。
・ランダム化(Randomization):偏りを防ぐため、被験者や条件をランダムに割り当てる。
・反復(Replication):同じ条件で繰り返すことで偶然の影響を減らす。
・局所管理(Blocking):影響しそうな要因をグループ化して分析する。
この3つを守ることで、データの信頼性が飛躍的に高まります。
2. 図で理解する「実験群」と「対照群」
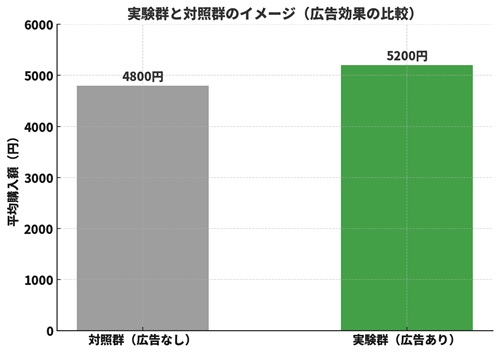
(左:広告なしのグループ=対照群、右:広告を見せたグループ=実験群)
たとえば、新しい広告キャンペーンの効果を検証したいとき、すべての顧客に広告を見せてしまうと比較ができません。広告を見せたグループ(実験群)と、見せなかったグループ(対照群)を分けて比較することで、広告の効果を正しく測定できます。
| グループ | 条件 | 平均購入額 | 結果 |
|---|---|---|---|
| 実験群 | 新広告を表示 | 5,200円 | ↑ 効果あり |
| 対照群 | 広告なし | 4,800円 | 基準値 |
「実験群」と「対照群」を比較することが、因果を特定する第一歩です。
3. ランダム化の重要性
実験では、参加者やデータを「公平に」割り振ることが何より大切です。もし年齢や地域などに偏りがあると、その差が結果に影響してしまう可能性があります。
ランダム化を行うことで、意図せぬバイアス(偏り)を排除し、純粋に施策の効果を見極められます。

(顧客全体を無作為にシャッフルし、半分を実験群、半分を対照群に分ける)
4. 反復と局所管理
1回の実験結果に頼りすぎるのも危険です。偶然の要因で結果が変わることは多々あります。
そのため、反復(Replication)を行い、同じ条件で何度もテストすることが重要です。
また、局所管理(Blocking)では、条件をコントロールして比較の精度を上げます。たとえば「地域別」「時間帯別」「デバイス別」など、結果に影響しそうな要因をグループ化して分析します。
5. 実験結果の解釈で気をつけること
良い実験をしても、解釈を間違えると意味がなくなります。以下の点に注意しましょう。
・効果が「統計的に有意」でも、実務的に意味があるとは限らない。
・データの分布や外れ値にも目を向ける。
・1回の成功に安心せず、継続的に検証する。
実験の結果は「判断材料のひとつ」であり、最終的な意思決定は文脈と目的に基づくことを忘れないでください。
6. ChatGPTで実験設計を支援する
ChatGPTを使えば、実験の設計をサポートすることも可能です。たとえば、以下のような指示を出すとAIが補助してくれます。
・「A/Bテストの対象をランダムに分けるExcel式を教えて」
・「広告効果の差が有意かどうかを判断する方法を教えて」
・「反復回数を増やしたとき、信頼区間はどう変わる?」
このようにAIを“統計のパートナー”として活用することで、実験の設計・分析・検証を効率化できます。

まとめ
・良い実験は「ランダム化・反復・局所管理」の3原則で成り立つ。
・実験群と対照群の比較が、因果関係を明らかにする鍵。
・結果を鵜呑みにせず、データの背景と文脈を読むことが大切。
・ChatGPTを活用すれば、実験設計をよりスマートに行える。
シリーズを通して、統計学の基礎から実践までを学んできました。データを見る力、考える力を育てて、次のビジネス判断に活かしていきましょう。
解説動画
実験計画法(DOE)でお悩みの方へ
直交表・分散分析・要因計画など、実験計画法の考え方と計算を数学のプロがマンツーマンで指導する実験計画法(DOE)個別指導をご用意しています。30分無料相談で、いまの理解度と学習プランを診断できます(オンライン・全国対応)。


新着記事



同じカテゴリーの新着記事



同じカテゴリーの人気記事

この記事に関連する教室: 統計・データ分析教室 → 社会人の学び直し講座 →